

DNA testing is a great tool for discovering your family history, and it’s more accessible than it’s ever been. With a simple cheek swab — no spit or blood necessary — you can get a percentage breakdown of your ethnic origins and find previously unknown relatives based on shared DNA. You can also confirm family relationships you know about. But what really goes on between swabbing the inside of your cheek and getting your results 4 weeks later? How does that little cotton swab translate into all of this fascinating and useful information?
Biological analysis
When you swab the inside of your cheek, epithelial cells stick to the cotton swab. Epithelial cells are easily accessible and can be collected in a noninvasive manner. The cells collected by the cheek swab are also germline cells, which means the DNA they contain is inherited from your parents (as opposed to somatic cells which include mutations that you acquire over your lifetime).
Inside each of these cells is a nucleus, and inside each nucleus is a copy of your DNA — your genetic material. DNA is a very stable molecule — it is not easily destroyed by changes in temperature or by being knocked around in the vial. That’s why you can simply mail it to the lab using the regular postal service without any special precautions like dry ice or special packaging.
You can see what the process in the lab looks like in the video below. The video also includes an explanation of the process our lab technicians use to isolate the DNA from your sample and prepare it for analysis.
Once it arrives in the lab, we prepare your DNA for our genotyping assay, a process that analyzes whether you have an A, T, G, or C nucleotide at specific variable locations in your DNA sequence. This is a very accurate method for determining how similar or different your DNA is from everyone else’s in our fast-growing DNA database.
First, the DNA is isolated from everything else in the vial: the liquid, the cotton swab, and the parts of the cell that are not the DNA itself.
The amount of DNA that we are able to extract from the sample you send is very small — too small to work with. This is why we must first amplify the sample by making many copies of your DNA sequence. We focus on the 700,000 sections that are known to vary between people (the other 99.9% of the sequence is pretty much the same for everyone). These sections are called SNPs.
After that, these amplified sections, or fragments, are poured onto a small chip with many pores. Inside each pore is a bead which binds specific DNA fragments. The fragments that were amplified and poured over the beads bind naturally to their individual beads, which allows the next step in the process to be informative. The next process tags each fragment with either a red or a green fluorescent signal.
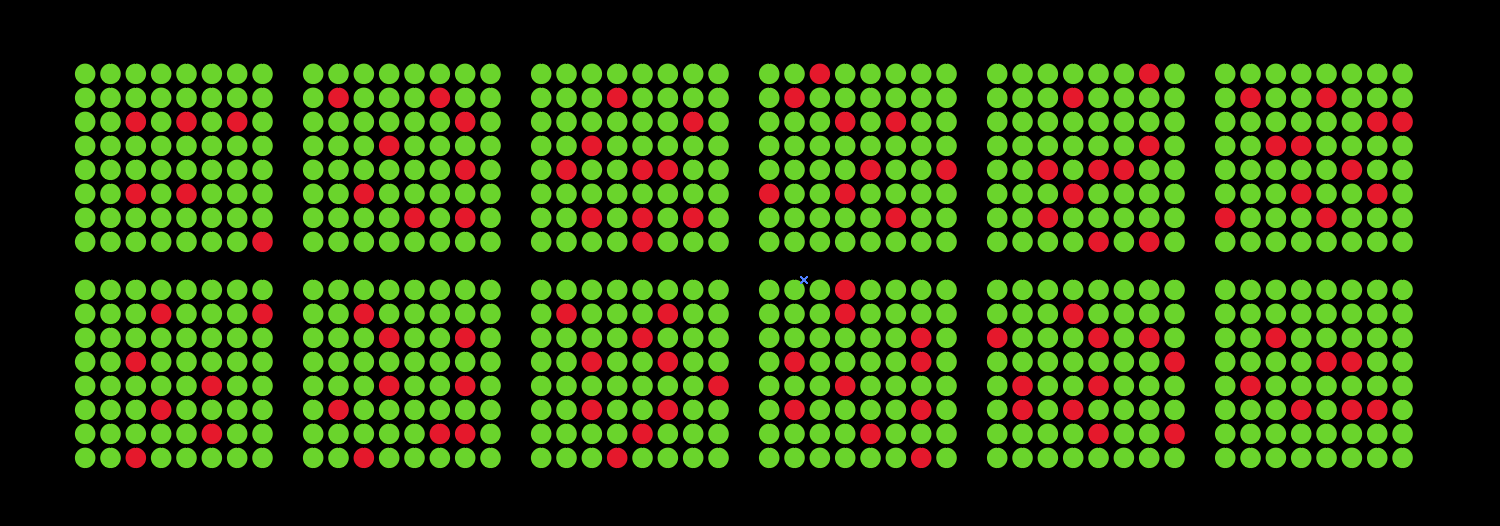
Specialized software is then able to read the chip and translate the colors into A’s, T’s, G’s, and C’s. The file with that sequence is the input for the next phase: computational analysis.
Computational analysis
After the genotyping, our analysts look at the digital output created by the computer that scanned the chips. This file of A’s, G’s, C’s, and T’s is the input for the computational process that comes next.
We start with phasing. Within each pair of chromosomes, one chromosome is passed down from the mother and one from the father. The genotyping technology that reads your DNA sample determines which genotypes you inherited from your parents for each SNP, but it doesn’t tell us which groups of variants were co-inherited from the same parent. Phasing helps us sort this out. It clusters the variants inherited from each of your parents into two separate groups — one group of maternal variants and one group of paternal variants.
After phasing, the analysts use imputation to infer the SNPs we did not read in the genotyping assay. Think of imputing DNA as reading a sentence with some of the letters missing — there’s a good chance that you can infer the missing letters from context. Not all DNA service providers read the same SNPs. To find DNA Matches for individuals who used different DNA companies, it is important to infer the SNPs that were not read before comparing results.
Then we use sophisticated algorithms to prepare your Ethnicity Estimate and identify your DNA Matches. For your Ethnicity Estimate, your variants are compared to models of 42 different ethnicities, and then we provide a breakdown of which percentages of your DNA match each of the different models — results that are made possible thanks to our Founder Populations Project. For your DNA Matches, your DNA segments are compared to everyone else’s in our DNA database to find similar sequences that indicate that a given segment was likely inherited by two or more people from a common ancestor or ancestors.




